



배경
Data, Now (as of 2021)
수 백 테라바이트의 데이터를 가진 큰 회사부터, 비교적 작은 사이즈의 데이터를 이제 쌓기 시작한 회사까지 많은 회사들이 데이터 웨어하우스 및 데이터 레이크를 구축하고 있다. 사실 데이터의 중요성은 말할 것도 없을 듯. 가만히 있어도 여기저기 빅 데이터, 마이 데이터 이야기가 들리고 AI나 머신러닝 등의 기술들을 쓰기 위해서는 데이터 필수 요소이다.
"구슬이 서말이라도 꿰어야 보배다"
데이터를 쌓았으면 활용을 해야한다. 많은 유즈케이스들이 있는데, 보통 비즈니스 의사결정에 필요한 지표를 뽑는 것으로 시작을 한다. 좀 더 고도화 된 곳들은 쌓아 놓은 데이터를 조회하는 것에 그치지 않고 머신러닝 관련 기술들을 활용해서 프로덕트에 새로운 피쳐로 적용하고, 인하우스 툴들로써 활용하고, 그 외 다양한 방법으로 비즈니스에 적용할 수 있다.
좀 더 개인적인 이야기를 덧붙이자면, 지금 내가 있는 회사는 빅쿼리 기반으로 데이터 웨어하우스를 구축하고 사용한 지 만 3년이 되어간다. 그 동안 많은 히스토리컬 데이터가 빅쿼리에 쌓여있는 상황이고, 이를 이용해서 머신러닝을 통해 많은 문제들을 해결하고 있다.
하지만 많은 데이터가 쌓여있는 곳에 다양한 사용처가 생겨남에 따라 그로 인해 문제점들이 스멀스멀 생겨나기 마련이다.
1.
데이터 퀄리티
데이터도 시간이 지남에 따라 지속적으로 변화할 수 있고, 그에 따라 데이터 퀄리티가 떨어지는 경우를 만나게 된다. 크게 두 가지 경우가 있을 수 있는데, 1) 자연스러운 데이터 shift, 2) 잘못된 로직, 핸들링하지 못한 외부 요소 등에 의한 오류 이다. 보통 많은 경우 2번 처럼 사람의 예상 범주 안에 없는 Edge Case가 생기거나 단순한 휴먼 에러로 인해 데이터 오염되는 경우가 많다.
2.
데이터 버전 관리
위에서 말한 것 처럼, 데이터가 지속적으로 변화함에 따라 데이터 파이프라인들에도 변화가 생긴다. Spark 기반의 데이터 파이프라인을 구성하는 코드는 보통 git으로 관리가 되는데, 이로 인해서 생겨나는 데이터에 대한 관리는 쉽지 않다 (DW 쪽에서 테이블 label 또는 테이블 컬럼으로 버전을 보통 관리하는 듯). SQL 기반의 파이프라인은 더 더욱 어렵다. SQL을 코드로 관리하지 않는 한, 변경 사항을 추적하기 힘들고 또한 SQL 특성상 복잡한 파이프라인을 만들때 500 라인이 넘어가는 SQL 코드를 한 줄 한 줄 읽어가면서 피어 리뷰를 받기도 쉽지 않다.
3.
데이터 오너쉽
데이터는 사내 모두의 것이 아닌가? 하는 의문이 생길 수 있지만 현실은 그렇지 않다. 중요한 데이터일 수록, 데이터에 문제점이 생겼을 때 누군가는 관련 사항을 고쳐야하고, 코드와 같이 누군가 로직을 변경했을 때 리뷰를 하고 새로운 버전을 배포할 오너십을 가질 사람이 꼭 필요해진다.
4.
데이터 의존성 파악
가지고 있는 데이터가 늘어나면 늘어날 수록 팩트/디멘션 테이블과의 조인이나 다른 테이블의 업데이트 상태에 따라서 다음 테이블이 생겨나게 되는 (보통 DAG로 표현 가능한) 로직들이 많이 생겨난다. 때문에 누군가가 기존에 있는 테이블 및 데이터세트들을 지우거나 변경하게 될 떄 사이드 이펙트가 생길 수 있다. 이와 같은 데이터 간의 디펜던시를 파악하기 어려운 환경이라면 안전하게 데이터를 다루기 힘들다.
체계적인 데이터 관리의 필요성
위와 같은 문제를 해결하기 위해서 나오고 있는 데이터 관련 용어들이 몇 가지 있다.
1.
Data Catalog
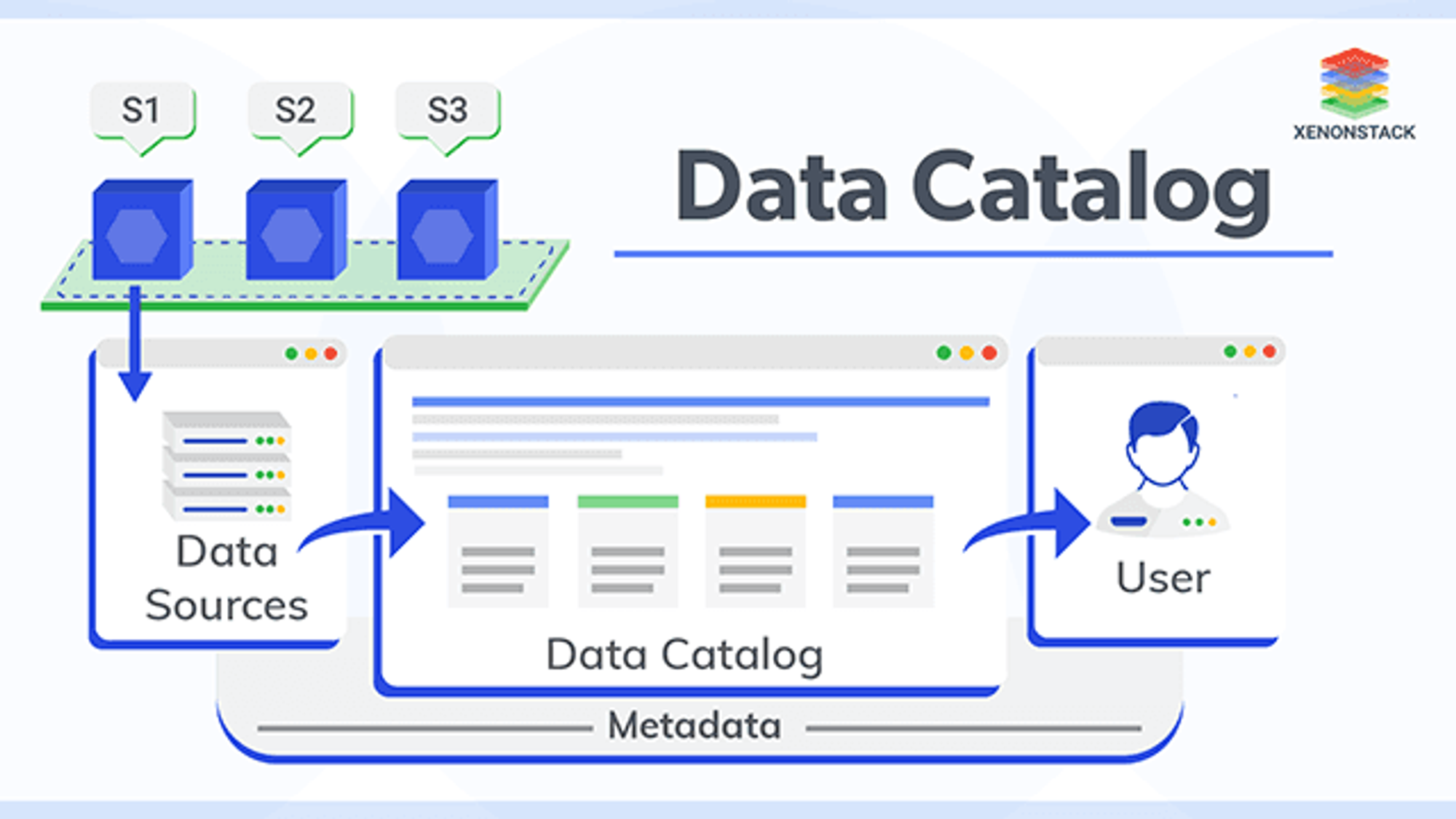
데이터 카탈로그는 메타데이터를 모아서 효과적으로 데이터를 관리할 수 있게 도와준다. 대표적으로 AWS Glue Catalog가 클라우드 프로바이더에서 제공하는 Data Catalog 이고, 빅쿼리나 스노우플레이크의 경우는 아예 Data Warehouse가 카탈로그의 역할도 담당한다. 또한 Databricks의 Delta Lake도 이와 같은 역할을 해주는 솔루션으로 알고 있다.
2.
Data Observability
3.
Data Lineage
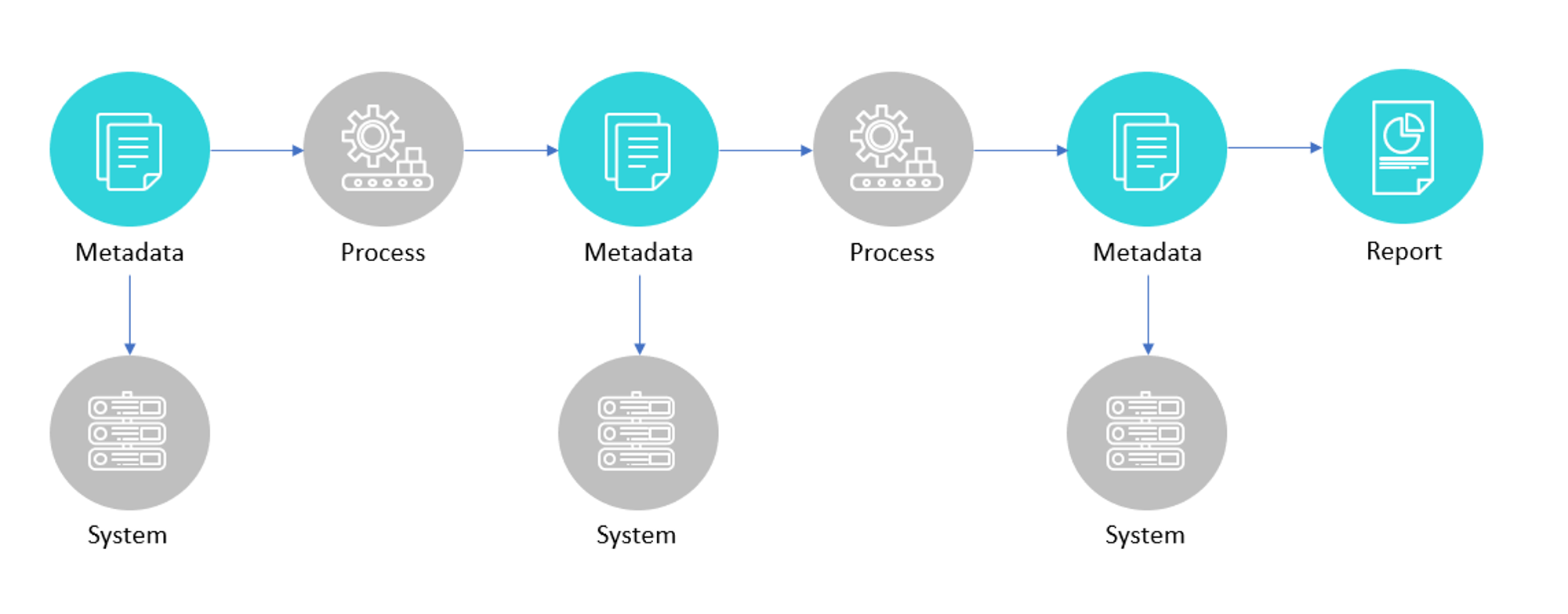
데이터 리니지(!)는 카탈로그와 마찬가지로 메타데이터를 효율적으로 관리하는 방법이다. 데이터의 흐름을 시각화하고 계보로 구현해서, 데이터 버전관리 및 의존성 파악 문제를 해결한다
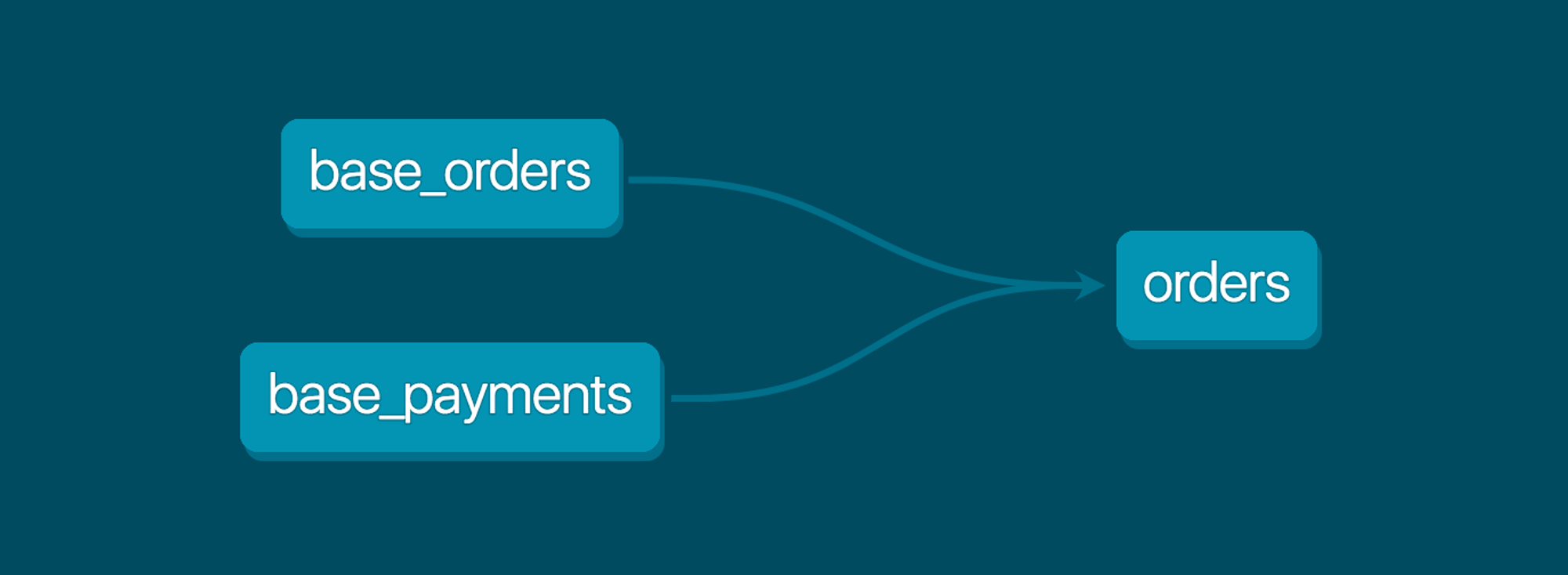
출처: dbt introduction
이외에도 현대적인 데이터 인프라에는 Data Governance, Data Mesh 등 다양한 용어들이 쏟아져 나오고 있고, 모두 다 적용해야 하는 거라기 보다는 각자의 상황에 맞는 방법론으로 실제적인 문제 해결에 포커싱하는 게 좋을 듯하다.
더 궁금하다면,

여기 시리즈에서 다양한 최신 데이터 스택들을 알 수 있다.
오늘 소개할 dbt는 Data Lineage라는 방법으로 위에서 이야기한 문제를 해결하고, 그와 더불어 ELT 파이프라인에서 T(Transform)에 집중한다.
dbt가 뭐에요?
data build tool의 약자로, 추출 - 변형 - 적재 중 변형을 쉽게, 더 자세히는 SQL 기반한 변형을 쉽게 하기 위한 도구이다.

(Spark 클러스터와 통신하는 플러그인을 지원하지만, python/scala를 활용하는 게 아니라 thrift/http 서버와 통신하면서 HiveQL을 날리는 형식으로 보인다).
Gitlab, Grailed, Slack, Notion 등의 회사에서 널리 쓰이고 있다. (하지만 국내에 유즈케이스는 아직 알려지지 않은 듯)
한 줄로 요약하자면,
ETL 중 T에만 집중하는 SQL 기반 Transform 도구
라고 할 수 있겠다.
CLI vs Cloud
CLI 모드는 python 패키지로 dbt를 설치해서 사용한다. YAML을 사용해서 테이블의 메타 데이터 및 유닛 테스트 관리, Jinja Template을 통해서 다양한 매크로 및 udf를 사용할 수 있고, 테이블 간의 디펜던시를 계산해준다. 또한 CLI 모드는 무료(!) 이다. 더 자세한 내용은 아래에서 다룰 예정.
Cloud 모드는 유로 서비스다. CLI에서 제공하는 모든 기능을 제공하고, 거기다가 SQL 통합 개발 환경(IDE)을 제공한다. 웹 IDE를 통해서 분석가 및 SQL 사용자가 소프트웨어 개발자 처럼 자신의 테이블에 대해 Unit Testing, 작업 관점에서 Pull Request와 기본적인 Git Branch 작업환경을 제어할 수 있게 해줌으로써, SQL 개발 프로세스를 전반적으로 유지보수 하기 쉽게 해준다. 또한 CronJob 또한 만들 수 있게 해준다. dbt Cloud 서비스의 프라이싱은 다음과 같다.
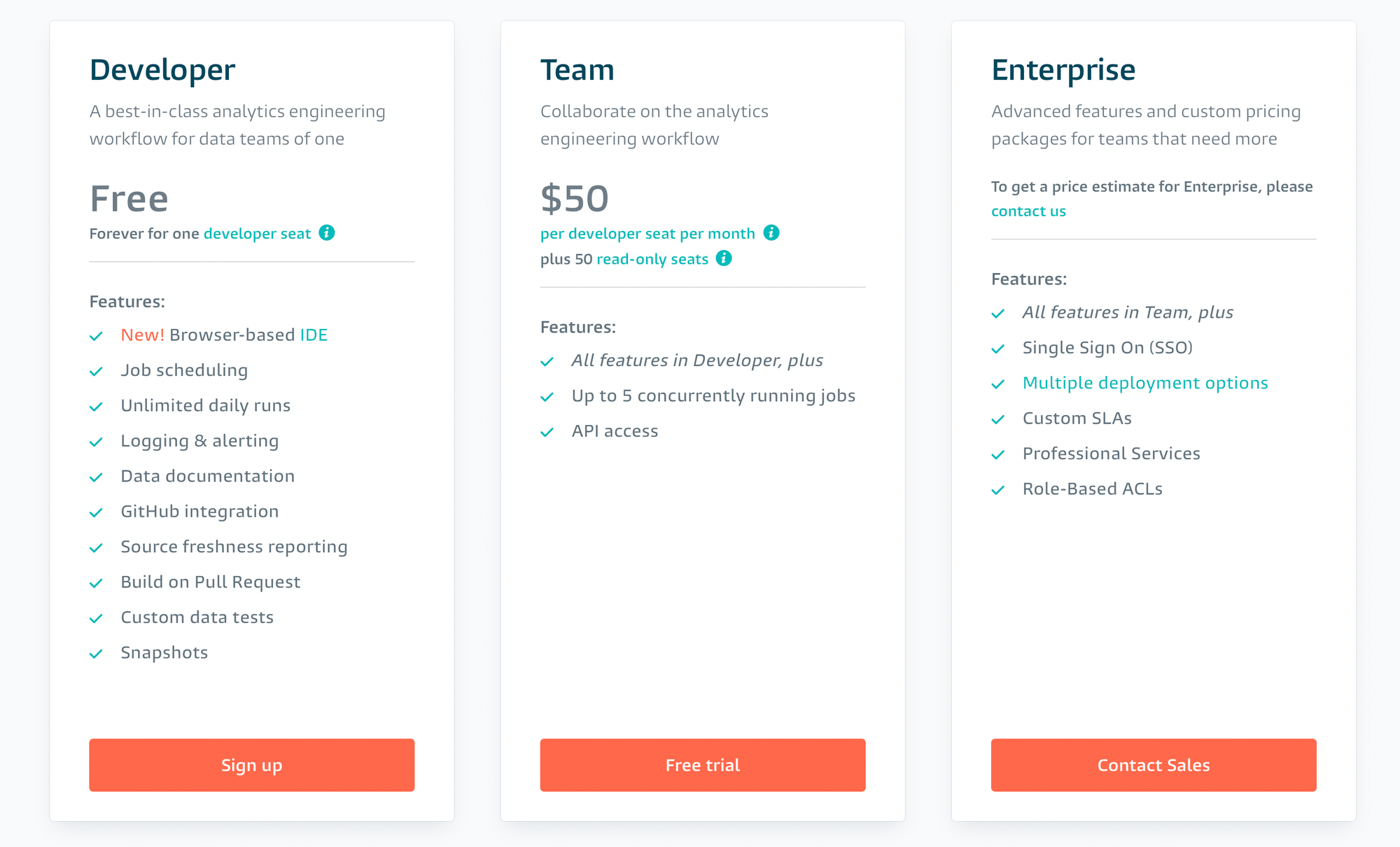
개인적으로 느낀 dbt cloud의 강력한 셀링 포인트는 웹 인터페이스에서 dbt 작업에서 귀찮은 부분들(컴파일된 쿼리 확인, 결과 확인, git 작업 등)을 간소화시켜준다는 데에 있다. 하지만 dbt CLI로도 웬만한 기능들은 모두 다 할 수 있다. (무엇보다 한 사람당 월 50불이라니 비싸다...)
어떤 장단점이 있을까요?
실제 회사에 dbt를 도입하게 되면서 느낌대로 정리해보자면
장점
•
다양한 데이터 유닛 테스팅으로 기존의 파이프라인을 더욱 견고하게 할 수 있다
•
직관적인 Docs UI로 데이터를 찾기위한 커뮤니케이션 비용을 절감할 수 있다
•
길어지는 SQL을 재사용가능한 여러개의 모듈들로 쪼갤 수 있다.
•
(dbt는 아니지만) 코드 및 개발 사이클로 SQL을 관리하기 때문에, SQL 리뷰 및 스타일 컨벤션 등 체계적으로 쿼리 및 테이블들을 관리할 수 있다.
•
다양한 macro와 오픈소스 툴들이 존재한다
•
따로 클라우드 및 온프레미스 리소스를 사용하지 않고, 기존의 데이터 웨어하우스 리소스를 더욱 효율적으로 활용한다
•
SQL 기반 데이터 오퍼레이션에 대한 오버헤드를 줄여주므로, 테이블 모델링과 아키텍쳐적인 고민에 집중할 수 있다.
단점
•
YAML에 대해 체계적인 관리가 필요하다. 때문에 메뉴얼한 작업들이 생겨날 수 있다.
•
러닝커브가 있는 편이라 사내 교육 필요
•
Transform 만을 위한 도구라, Extract나 Load를 위해서는 다른 도구와 같이 사용해야 한다.
•
CLI 만 사용하는 경우, 어떤 쿼리가 나가는 지 모니터링하기 쉽지 않다.
◦
bigquery adapter 등에는 위한 max bytes billed limit을 걸 수 있는 듯 잘 제어할 수 있는 장치가 존재한다
dbt 도입을 고려해야할 때
•
SQL 기반의 데이터 조회 및 테이블 생성이 많을 때
•
MPP 기반 데이터 웨어하우스를 사용하는 ELT 파이프라인 환경일 때
◦
전통적인 ETL 파이프라인에는 보통 Transform과 Load가 같이 되는 경우가 많다(Pyspark로 df.read한 다음 df.write 한다거나...)
◦
dbt는 transform하기 위한 라이브러리지 load를 하기 위한 서포트는 미약하다.
•
사내에 SQL 다루는 인원이 많을 때
◦
dbt는 SQL 기반으로 데이터 변형 작업을 수행하기 때문에 SQL을 다루는 인원이 많을 수록 생산성 면에서 더 큰 임팩트를 낼 수 있다.
•
높은 쿼리 비용 때문에 파생 테이블의 체계적인 관리가 필요해질 때
◦
BigQuery, Snowflake의 특성상 테이블을 만들어 내는게 기존의 RDBMS보다 훨씬 쉽다. 때문에 생기는 트레이드오프로 테이블들이 무분별하게 만들어지고 같은 테이블을 여러군데에서 만들어내고 때문에 쓸데없이 많은 데이터를 스캐닝해서 쿼리 비용이 높게 측정되는 경우가 많다.
◦
dbt를 통해서 테이블들을 체계적으로 관리하기 시작하면, 현재 어떤 테이블이 관리되고 있고, 누가 오너쉽을 가지고 있고, 어떤 컬럼 및 테스트로 관리되고 있는지 등 메타 정보에 대해서 파악하기 쉬워진다. 떄문에 장기적으로 봤을 때, 부득이한 경우를 제외하고 필요한 데이터를 찾는 공수와 쿼리 비용 또한 절감할 수 있다.
dbt 도입을 고려하지 않아도 될 때
•
사내에 SQL을 다루는 인원이 많지 않을때
•
하둡 기반 데이터 웨어하우스, Spark 기반 데이터 프로세싱이 더 익숙하고 잘 유지가 되고 있을 때
•
체계적인 메타 정보와 테이블의 관리보다, adhoc 요청을 처리하는 속도가 더 중요할 때
dbt의 기본 기능 알아보기
아래는 dbt cli를 기준으로 설명한다
모든 코드 및 개발 환경 구성은 아래 Github에서 찾아볼 수 있다.
dbt의 기능 데모를 위한 구성은 다음과 같다.
•
dbt 코드베이스
•
DW 모킹을 위한 Postgres Docker
•
(optional) devcontainer
Python 3.8.x 기반 dbt 초기 설정
또한 dbt가 현재 지원하는 데이터베이스 및 웨어하우스는 다음과 같다
•
BigQuery
•
Snowflake
•
Postgres
•
Redshift
•
MS SQL
•
Oracle
•
Presto
•
Apache Spark (Thrift, HTTP Server)
•
Microsoft Azure Synapse DW
•
Dremio
•
ClickHouse
와 같다. (dbt에서는 adapter로 표현)
dbt 프로젝트 구조
├── README.md
├── analysis
├── data
├── dbt_project.yml
├── macros
├── models
│ └── example
│ ├── my_first_dbt_model.sql
│ ├── my_second_dbt_model.sql
│ └── schema.yml
├── snapshots
└── tests
Plain Text
복사
초기 dbt 프로젝트의 구조이다.
•
data 에는 csv 파일 같은 데이터 피딩을 위한 정적 파일들이 들어간다. dbt seed 커멘드를 통해서 insert 쿼리를 날려서 데이터 웨어하우스/데이터베이스에 데이터를 적재할 수 있다. (예제)
•
analysis 는 테이블을 만들기 위한 SQL이 아닌, 분석만을 위한 SQL 파일이 들어간다. 실제로 dbt run 커멘드를 통해서 쿼리가 실행되지는 않고, compile 테스트 (dbt compile) 만을 위해서 사용된다
예제
•
•
macros 는 유저가 정의한 jinja template macro가 존재하는 디렉토리이다.
예제
•
•
snapshot 는 source 테이블들의 스냅샷에 대한 정보를 테이블로 만든다
예제
주로 source table과 같이 쓰인다. (e.g., 일간 배치로 꾸준히 insert 되는 테이블의 daily snapshot을 남기고 싶을 때)
•
tests 는 모델 및 스냅샷에 대한 테스트의 정의를 담는다
dbt 용어 정리
•
Model
단순히 말해서 테이블이다. models 디렉토리에 SQL 파일을 만들면, SQL 문법으로 CREATE TABLE AS, 또는 CREATE OR REPLACE TABLE 등의 문법으로 컴파일되어서 연결되어 있는 데이터 웨어하우스 및 데이터 베이스에 테이블을 추가한다. (때문에 Schema와 privilege를 잘 관리해두는 게 좋겠다) incremental 옵션을 주지 않으면 기존 테이블을 덮어쓰니 (BigQuery로 치면 TRUNCATE INSERT) 주의 해야한다.
•
Source
모델을 만들 때 원천 데이터/테이블을 말한다. 모델과는 달리 Source는 테이블을 덮어 쓰지 않는다. Best Practice에 따르면, Source를 그대로 사용하는 것 보다는 Staging 테이블을 만들어서 Source Table에서 컬럼들을 컨벤션에 맞게 rename하고, 필요하다면 간단한 where문이나 join을 통해서 작업하기 좋은 형태로 만들어 쓰는 걸 추천한다.
•
Schema
RDMS에 익숙한 사람들이라면 Database - Schema - Table 과 혼동할 수 있다. dbt의 Schema는 모델을 통해서 만들어질 테이블들에 대한 명세를 말한다 (e.g., table name, description, column name, test ...)
예제 schema.yml
•
Profile
dbt와 DW, DB를 연결하기 위한 메타 정보이다. 하나의 dbt 프로젝트는 보통 하나의 profile과 1대1 관계를 유지하는 게 좋아보인다. 더 자세한 정보는 dbt의 documentation에서 찾아볼 수 있다. 기본적으로 dbt 프로젝트를 만들면, ~/.dbt/profiles.yml 을 생성하고 사용한다. 하지만 협업 환경에서는 로컬마다 다른 profile을 사용하는 데에 제약사항이 있을 수 있어서 개인적으로 project 안에 profiles yaml을 만들어두고 --profiles-dir 플래그를 통해서 오버라이딩해서 사용하는 걸 추천한다.
예제 Profile yaml
•
Target
dbt가 실행할 환경이라고 보는 게 가장 정확할 듯. 대부분 dev/prod, dev/live 등으로 구성해두고, 개발 환경과 운영 환경에서 실행할 구성을 구분한다. 기본적으로 dbt 커멘드를 실행할 때 thread를 몇 개를 사용할 건지, (일부 adapter 한정) max bytes billed 등의 설정을 환경 별로 다르게 해서
초기 데이터 로드
1.
data 디렉토리에 csv 파일을 만든다
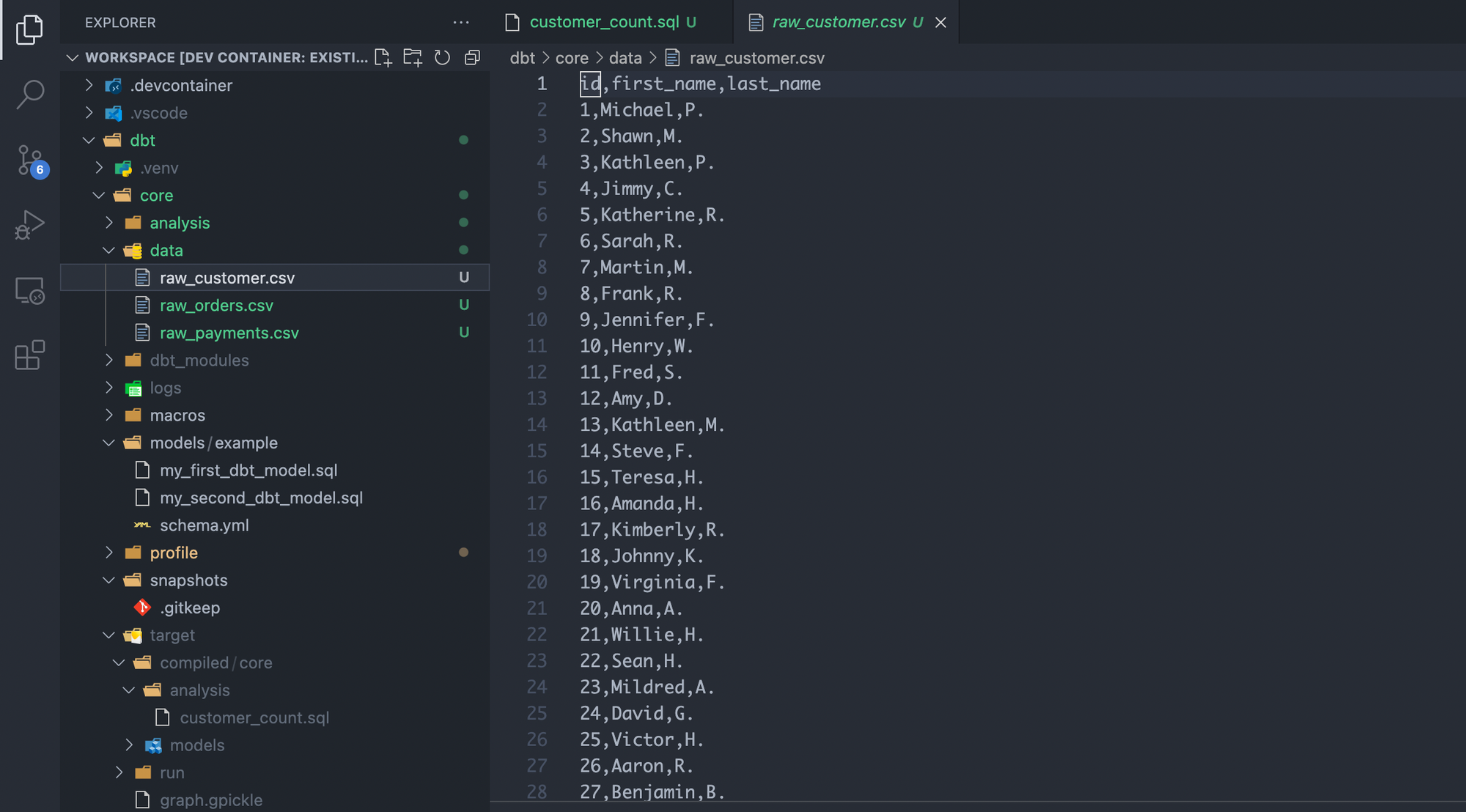
2.
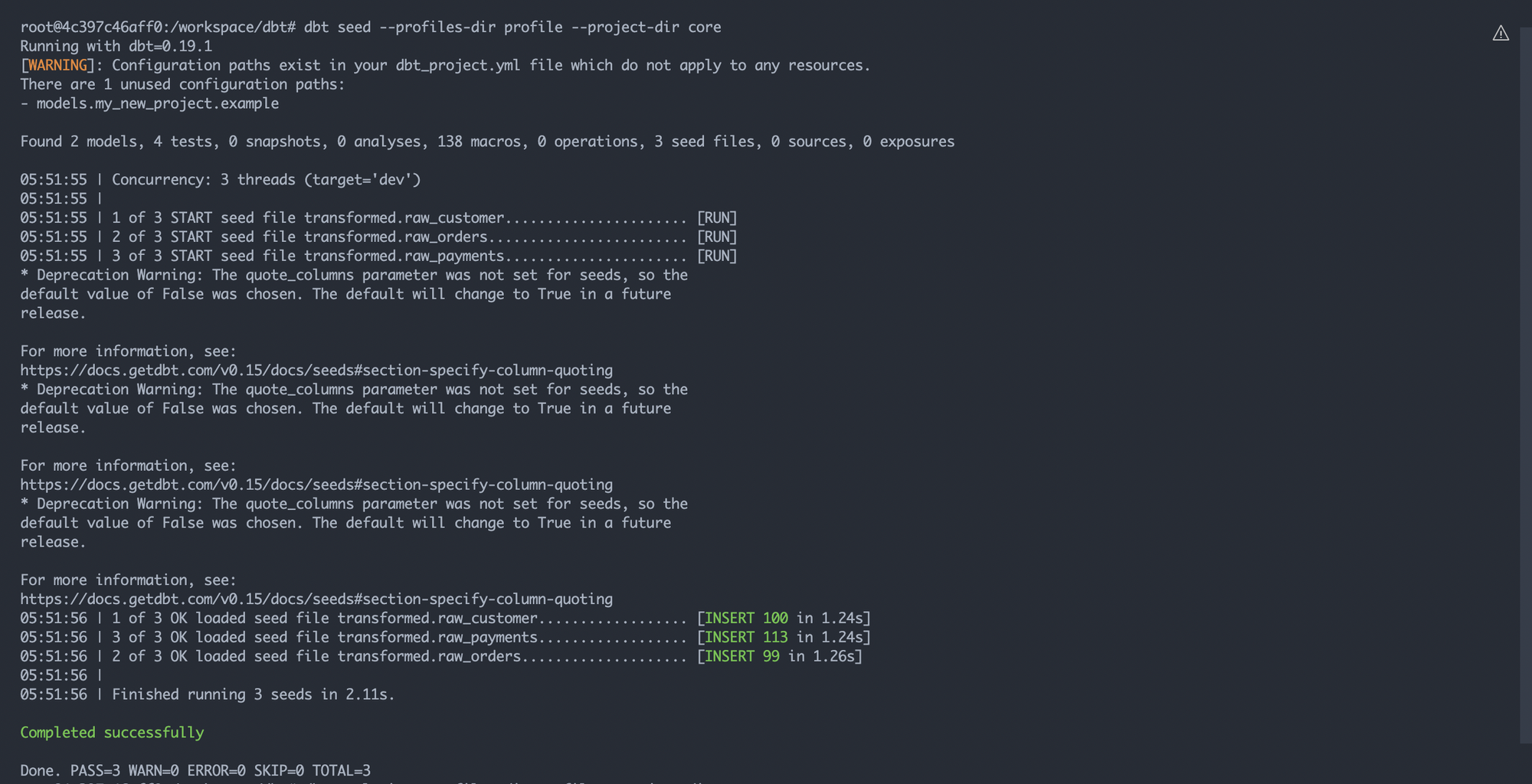
dbt seed 커멘드를 입력한다
3.
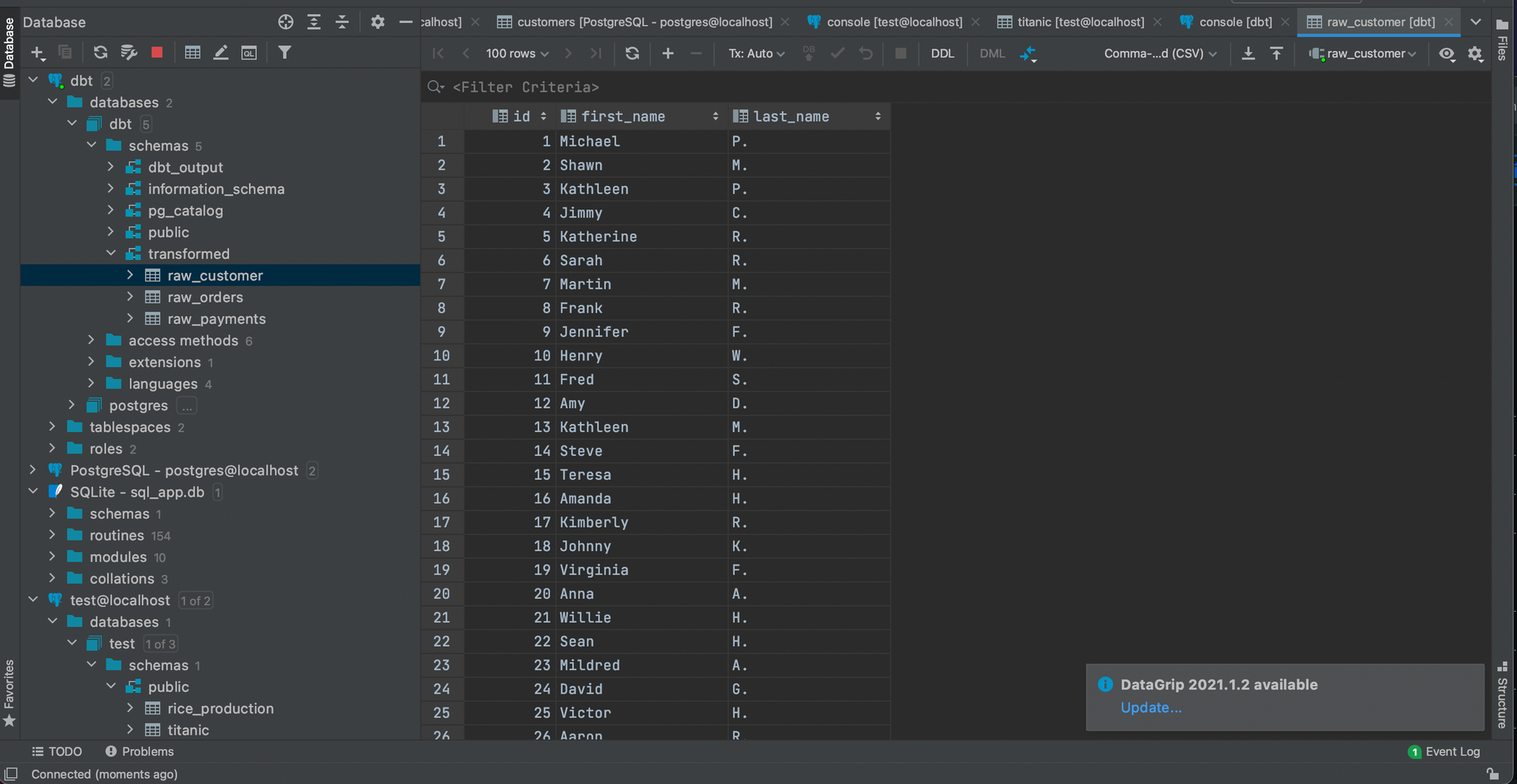
csv 파일을 기반으로 하나의 model 처럼 target에 테이블을 만들 수 있다
첫 model 만들어보기
1.
models/staging/stg_orders.sql 을 만든다
with source as (
select * from {{ ref('raw_orders') }}
),
renamed as (
select
id as order_id,
user_id as customer_id,
order_date,
status
from source
)
select * from renamed
SQL
복사
2.
dbt run 커멘드를 실행한다
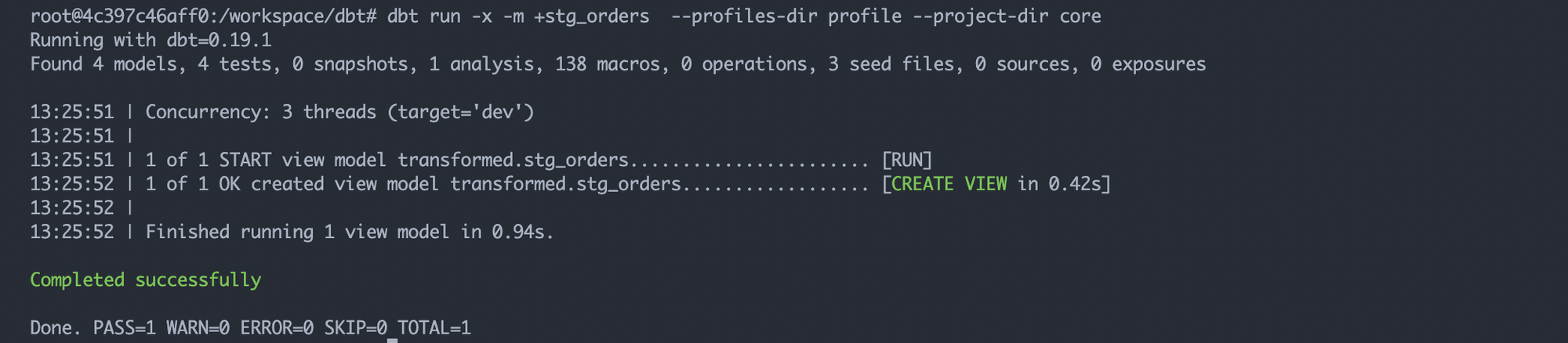
3. 테이블을 확인한다
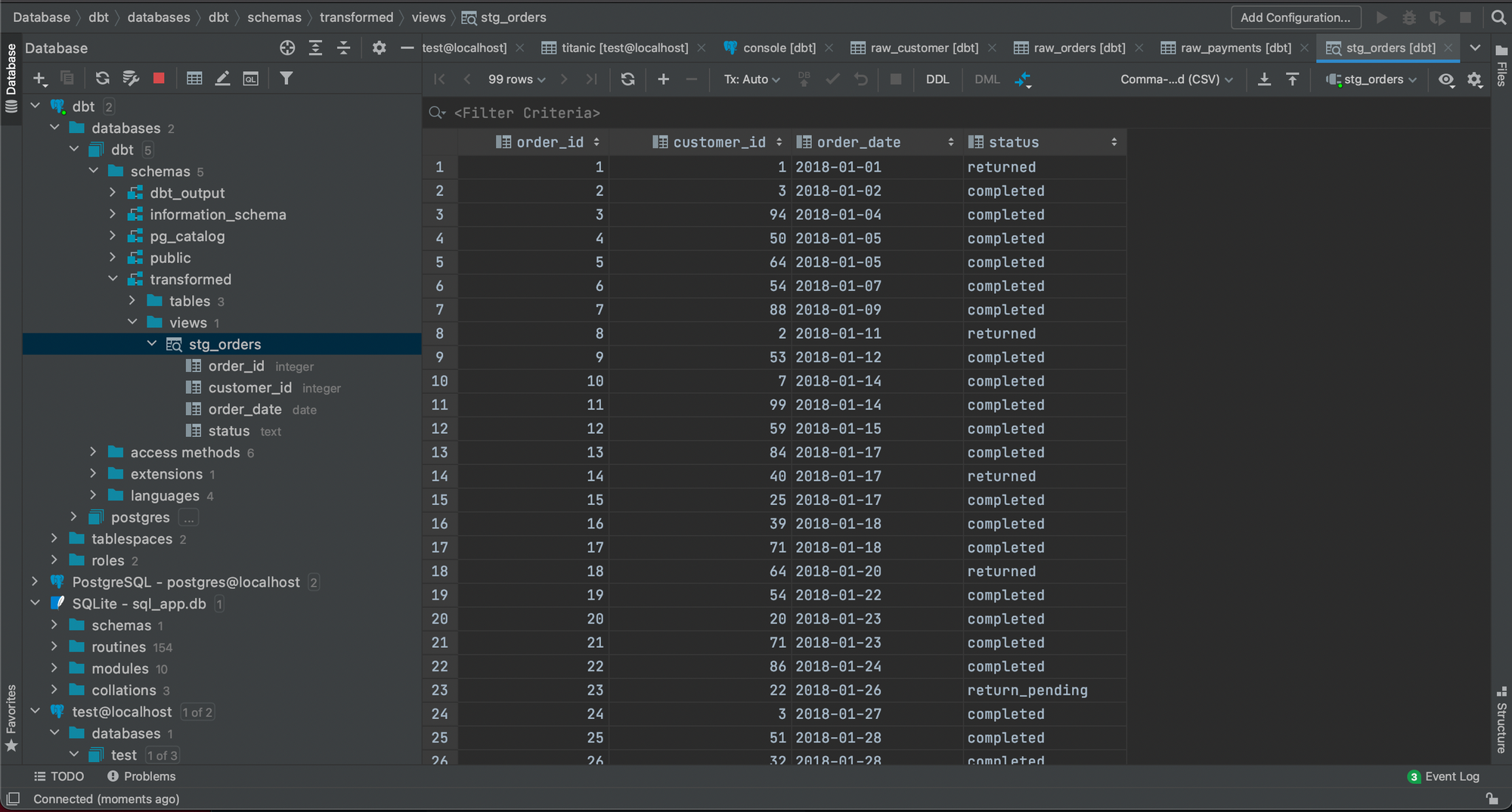
•
•
모델 selection 팁을 주자면, +model_name 을 --model 옵션으로 주면 해당 모델에 디펜던시가 있는 테이블들을 모두 빌드한다. 관련한 문법은 Gitlab의 dbt 가이드가 잘 정리해뒀다.
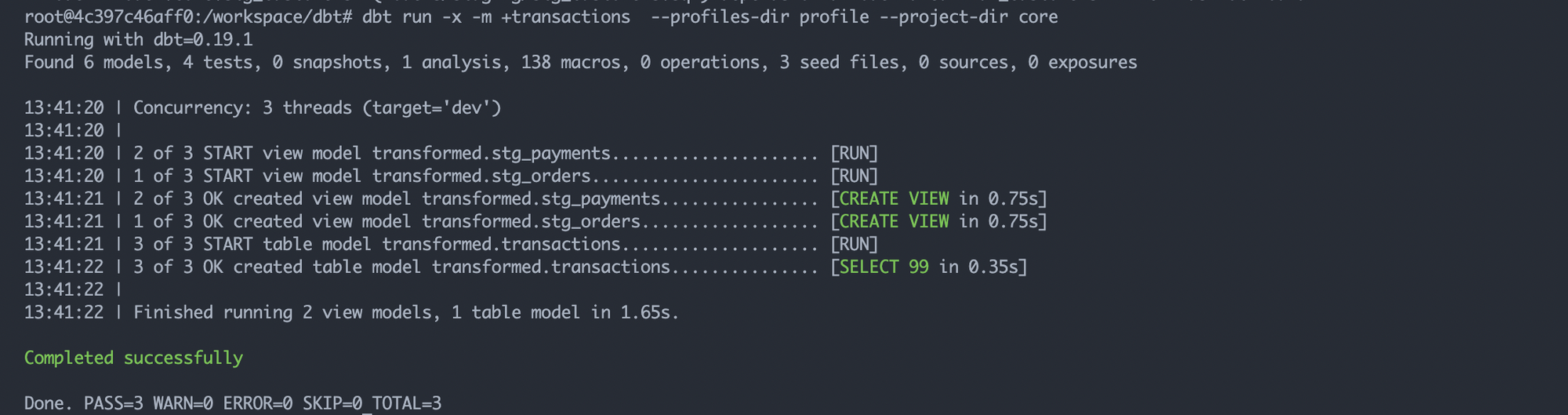
transactions라는 테이블에 엮여있는 payments, orders 등 테이블을 같이 업데이트 한다.
Documentation
현재까지 만든 dbt 모델들의 메타정보들을 두 개의 커멘드로 웹페이지로 만들어서 조회할 수 있다.
dbt docs generate
위 커멘드는 모델들을 compile해서 디펜던시 그래프를 그리고 그에 대한 메타정보를 target 폴더 (default는 그렇고 다른 이름으로 dbt_project.yml 에서 바꿀 수 있다)에 manifest.json , catalog.json 형태로 저장한다. 또한 그를 시각화할 index.html 파일을 만든다
dbt docs serve
간단한 webserver를 띄워서 localhost에서 조회할 수 있게한다.
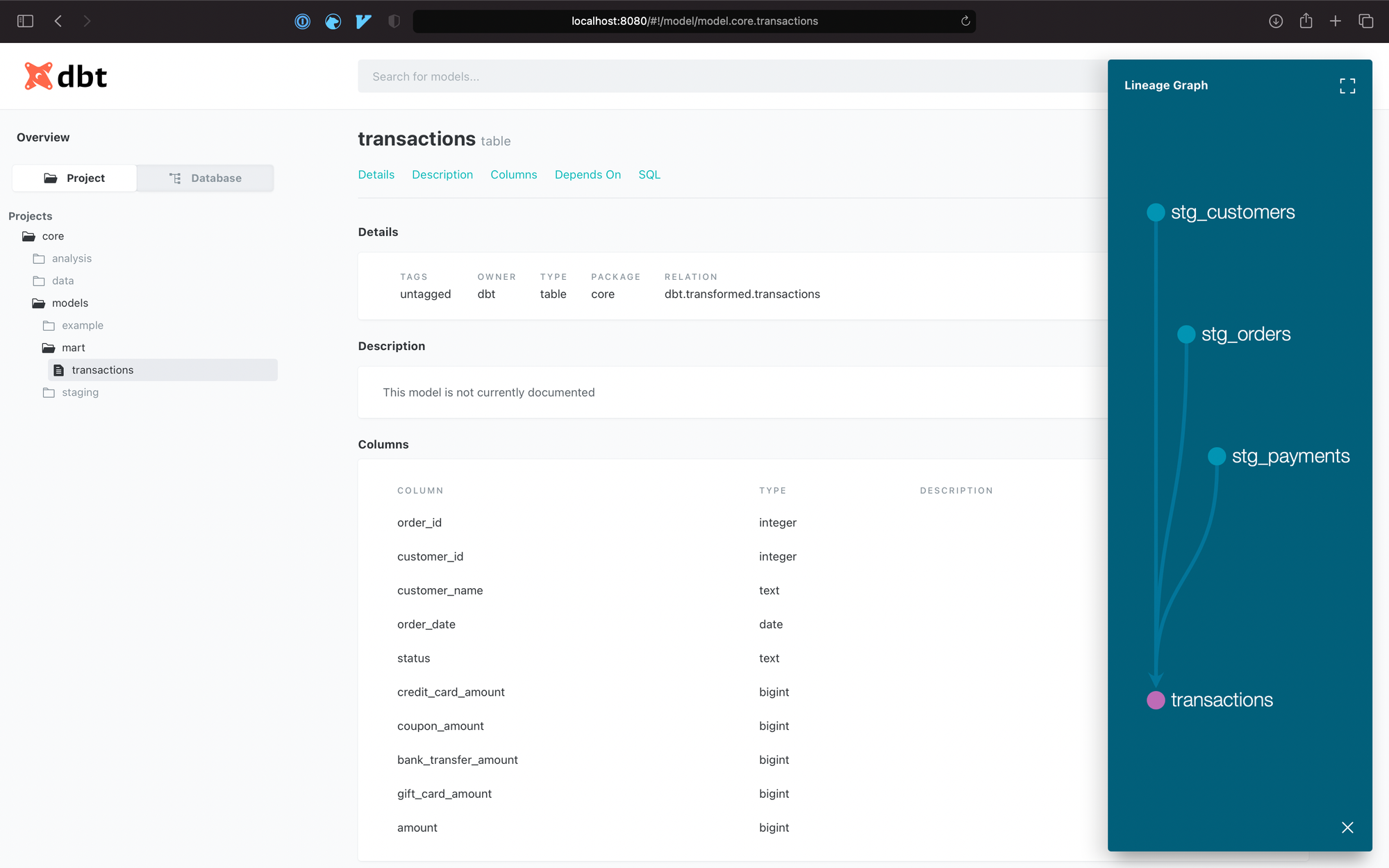
위의 스크린샷에서 보는 것 같이 위의 예제에서 만든 transactions라는 모델의 메타정보, 컬럼 정보, 그리고 의존 관계를 웹페이지 형태로 쉽게 볼 수 있다. description이 현재는 비어져있는데, 여기에 마크다운으로 이 테이블이 어떤 테이블인지, 간단한 로직 설명이라던가 다양한 방법으로 해당 테이블에 대한 문서를 남길 수 있다. (참고)
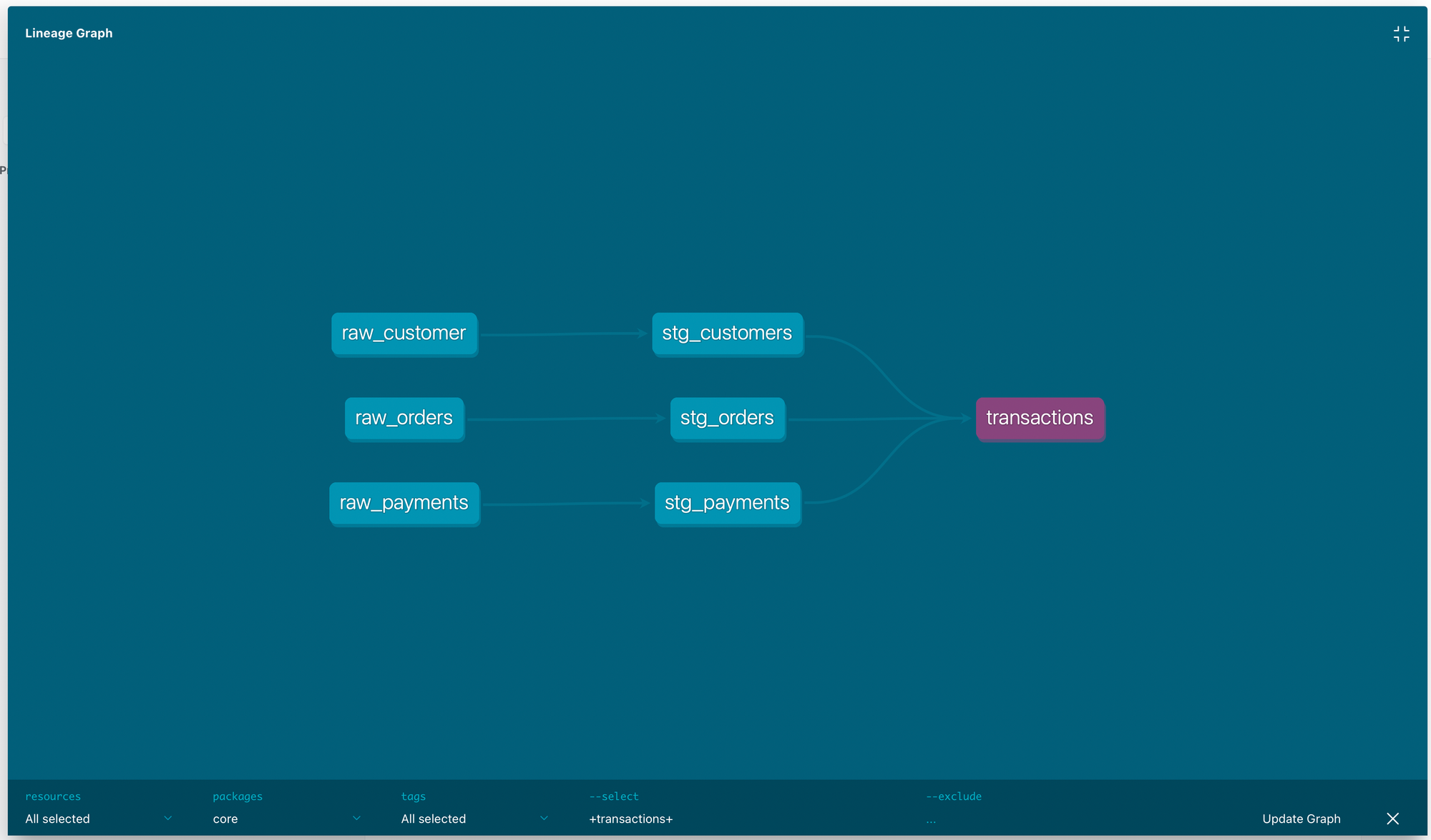
fullscreen view로 테이블의 디펜던시를 더 자세히 볼 수 있다.
첫 테스트 만들어보기
dbt에서 테스트는 크게 두 가지가 있다.
1.
dbt run하기 이전의 테스트
2.
dbt run한 후의 테스트
1번의 경우에는 source 테이블들에 데이터가 잘 들어가 있는지, 특정 컬럼이 non-null인지, unique한지 하는 기본적인 테스트 부터, 커스텀하게 테스트 macro를 작성해두면 더 많은 test case를 둘 수 있다 (예를 들어 특정 기간동안 daily updated row count가 n개 인데, 오늘의 row count는 이 분포에서 크게 벗어나지는 않는지... 관련해서는 회사 기술 블로그를 통해 더 자세히 설명하도록 하겠다)
2번의 경우는 dbt run 커멘드를 통해 만들어진 테이블에 대해서 예상한 대로 데이터가 잘 만들어 졌는지에 대해서 테스트 한다. 1번 케이스와 마찬가지로 다양한 테스트 케이스를 사용해서 파이프라인의 테스팅을 할 수 있다.
테스트를 추가하는 방법은 schema.yml(2번) 이나 source.yml(1번)에 한 줄 남짓한 코드를 추가하는 것 만으로 할 수 있다.
예제로 위에서 만든 transactions라는 모델에 데이터가 잘 들어갔는 지(2번) 테스트 케이스를 추가해보자
version: 2
models:
- name: transactions
description: 주문별 상세 정보를 담은 테이블
columns:
- name: order_id
tests:
- unique
- not_null
description: This is a unique identifier for an order
- name: customer_id
description: Foreign key to the customers table
tests:
- not_null
- relationships:
to: ref('stg_customers')
field: customer_id
- name: customer_name
description: customers full name
tests:
- not_null
- name: order_date
description: Date (UTC) that the order was placed
- name: status
tests:
- accepted_values:
values:
["placed", "shipped", "completed", "return_pending", "returned"]
- name: amount
description: Total amount (AUD) of the order
tests:
- not_null
- name: credit_card_amount
description: Amount of the order (AUD) paid for by credit card
tests:
- not_null
- name: coupon_amount
description: Amount of the order (AUD) paid for by coupon
tests:
- not_null
- name: bank_transfer_amount
description: Amount of the order (AUD) paid for by bank transfer
tests:
- not_null
- name: gift_card_amount
description: Amount of the order (AUD) paid for by gift card
tests:
- not_null
YAML
복사
models/mart/schema.yml
위와 같이 yml 파일에 모델에 대한 documentation과 테스트 케이스를 같이 써줄 수 있다.
테스트를 실행하기 위해서는 dbt test 커멘드를 사용한다
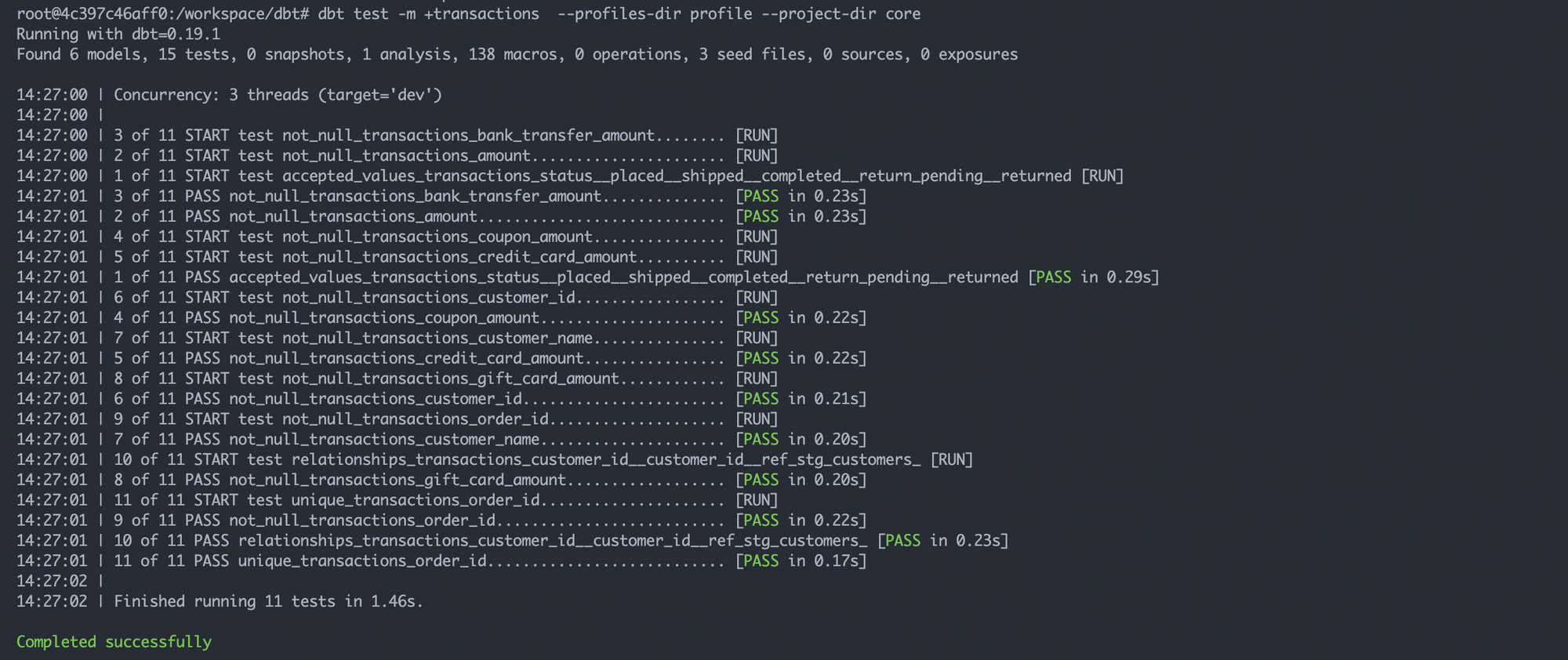
위의 예제 테스트는 dbt에서 기본적으로 제공하는 테스트 케이스만을 사용했다. 구체적으로 어떤 쿼리를 통해서 테스트를 수행했는 지 알아보려면, target/compiled 디렉토리를 살펴보면 된다. 그 중 schema.yml에서 status 컬럼에 대한 테스트가 어떻게 쿼리로 변환됐는지 살펴보자면,
with all_values as (
select distinct
status as value_field
from "dbt"."transformed"."transactions"
),
validation_errors as (
select
value_field
from all_values
where value_field not in (
'placed','shipped','completed','return_pending','returned'
)
)
select count(*) as validation_errors
from validation_errors
SQL
복사
위 쿼리의 결과는 0 또는 1 이상의 값이 나오게 된다. 0이 나오면 Pass하고 아니라면 fail하게 된다. 이와 같이 dbt 에서 테스트는 SQL을 통해서 쿼리의 결과물이 0 또는 다른 값이 나오는 지를 통해 간단하게 컬럼 및 테이블에 대한 테스팅을 할 수 있어서 기본적인 SQL 지식만 있어도 다양한 테스트 케이스를 커버할 수 있다.
마치며
위에서 본 것 같이 dbt는 SQL 만으로 현대적인 데이터 인프라의 다양한 문제를 해결하는 데 도움을 준다. 높은 비용을 감수해야하는 분산 처리 시스템에서 프로세싱 해야하는 기존의 데이터 프로세싱 방법들과는 달리 프로세싱은 Data Warehouse의 기능에 위임하고, Jinja 템플릿을 활용해서 모듈화로 재사용가능한 블록으로 만들고, YAML로 간단하게 문서화 및 테스트 케이스를 추가하고, 웹페이지로 메타 정보들을 조회할 수 있게해서 데이터를 관리하는 조직과 소비하는 조직간의 커뮤니케이션 비용을 줄여줄 수 있다.
이 글에서 더 자세한 내용을 다루고자 했지만, 배경 설명부터 기본적인 기능을 알아보는 것만으로 글이 너무 길어져서 좀 더 고급 기능들과 실제 프로덕션 환경에서 운영하면서 얻게된 팁들이나 러닝들을 다음 글에서 정리해보고자 한다. 예를 들어,
•
Airflow 커스텀 dbt operator로 빠르고 안정적으로 SQL 기반 데이터 파이프라인 만들기
•
pre-commit + sqlfluff로 SQL 코딩 컨벤션 관리하기
•
커스텀 macro와 dbt package로 dbt 코드 베이스 더욱 효율적으로 데이터 관리하기
•
좀 더 자세한 모델 layer 분리 및 유지보수 하기 쉬운 dbt 자잘한 팁들
•
dbt기반 Data Observability 대시보드 구성하기
등이 있다.
위에서 언급한 것과 같이, 현재에도 많은 회사에서 하둡 기반의 데이터 인프라나 dbt를 적용하기 힘든 환경에서 운영중이다. 입버릇 처럼 하는 말이지만, 은총알은 없다. 데이터 인더스트리에 하루하루가 다르게 새로운 기술들이 나오고 있고, dbt 또한 하나의 fling일 수도 있다.
개인적인 생각을 덧붙히자면, 이전보다 훨씬 많은 곳들이 ETL보다는 ELT 패러다임으로 데이터 인프라를 만들어가고 있는 추세이고 (물론 ETL에서 아예 못쓰는 건 아닌 거 같지만...), 기존에 가파른 러닝커브를 가지고 있지만 넓은 유저 베이스를 가지고 있던 Apache Spark 대신 고려해볼 수 있는 기술이라고 생각한다.